Добрый день, коллеги. Готовимся к запуску одного проекта, к сожалению, по NDA не могу рассказать что за проект, позже, после старта, напишу пост, но появилась проблема.
К моменту старта мы ожидаем высокие нагрузки и нам немного сложно оценить необходимую инфраструктуру под них. В пике мы ожидаем ~5 млн MySQL запросов в минуту (60% Select / 40% Insert). Запросы по себе довольно простые т.е. без сложных выборок и т.д. Подскажите пожалуйста оборудование, которое все это переварит. Нам предложили 2 8-и гиговых кор 2 дуо под веб и 3 8-и гиговых кор 2 дуо под базу данных.
Добрый день, коллеги. Готовимся к запуску одного проекта, к сожалению, по NDA не могу рассказать что за проект, позже, после старта, напишу пост, но появилась проблема.
К моменту старта мы ожидаем высокие нагрузки и нам немного сложно оценить необходимую инфраструктуру под них. В пике мы ожидаем ~5 млн MySQL запросов в минуту (60% Select / 40% Insert). Запросы по себе довольно простые т.е. без сложных выборок и т.д. Подскажите пожалуйста оборудование, которое все это переварит. Нам предложили 2 8-и гиговых кор 2 дуо под веб и 3 8-и гиговых кор 2 дуо под базу данных.
Задача следующая: предоставить доступ к 16Gb данных (около 220 отдельных кусков поставляемых по отдельности и используемые самостоятельно. Что-то похожее на видео клип) для 30млн. пользователей (да, аудитория большая).
Каждый пользователь должен иметь возможность скачать любую из частей по-отдельности, но должен быть лишен возможности передавать доступ своей части иному лицу. (что-то вроде уникальных URL для каждого пользователя).
Так же перед отдачей каждого из кусков 10% данных должны быть зашифрованы асинхронными ключами. (где-то 20мб для каждого пользователя)
По специфике сервиса, один пользователь в 80% случаев свою часть будет скачивать только разово. 15% дважды и менее 5% более 2х раз.
Проблематика: мы даже представить не можем нагрузку, но аналитики подсказывают что со старта будет около 50 тыс. пользователей с 10-15% приростом в неделю в течении 3х мес. Потом даже и не знаем на каком уровне все останется.
Вопрос: можно ли как-то прикрутить под эти задачи Amazon or Azure?
Нам бы не хотелось закупать оборудование, хотим аренду мощностей для шифрованная и отдаче контента.
Спасибо.
P.s. Даже и не спрашивайте что это за сервис и почему такие условия.
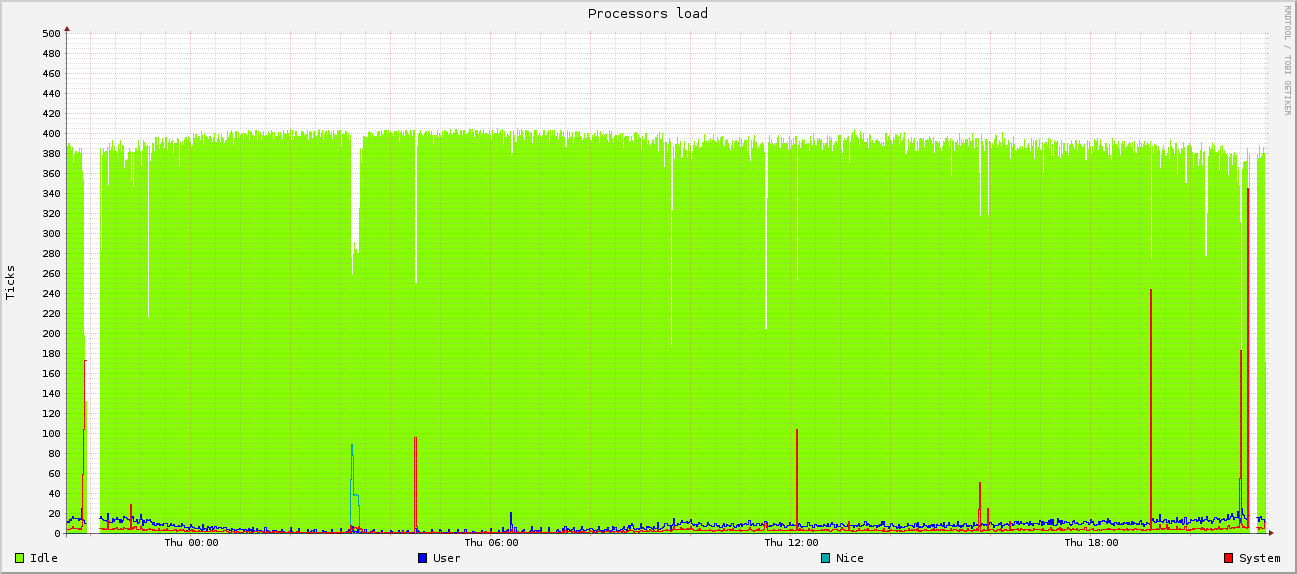
Есть сервер debian lenny с ядром 2.6.26-2-amd64. Проблема в том, что не могу продиагностировать, что периодически заставляет его задуматься на все 4 проца так, что становится недоступен извне. Не отвечает даже на ARP. Через некоторый промежуток времени его «попускает» самостоятельно.
Графички (по данным /proc/stat, 3я цифра) показывают, что пожирает некое system (кстати, что именно к этому оносится? ядро?):
Как я уже говорил, по сети машинка в это время недоступна. Поэтому непосредственно в этот момент список процессов глянуть нельзя. Пробовал собирать периодически и анализировать инфу ps'а, процесс внезапно повышающий показатель TIME после затупа отсутствует.
Подскажите плз, что это может быть, или хотя бы как удаленно продиагностировать/куда копать?
Подскажите что и где почитать на тему технологий и деталей построения периодических рейтингов(топов, чартов) для большого количества юзеров в условиях высоких нагрузок?
Буду рад ссылкам на презентации или статьи крупных проектов, сам я ничего не нашел=(
Или подскажите как это реализовать, какие хранилища использовать. Особенно важно, что рейтинги периодичны и для большого количества юзеров.
Есть сайт который отдает небольшие html странички и кучу графики. Задача поставить впереди ngnix, но так, чтобы он кешировал все кроме Content-Type: text/html.
На сам сайт доступа нету, там ничего поправить нельзя. Ткните носом пожалуйста, сам не могу найти решение.
Хотелось бы от хабралюдей узнать в чем мои суждения неверны. Итак, приступим-с.
Задача: построить сервис, с возможностью горизонтального масштабирования, который в будущем теоретически будет высоконагруженным.
Каковы мои размышления на тему, вопросы по каждому пункту прямо в нем:
— имеется домен (имя взято с потолка) hls.com
— у регистратора у этого домена прописано максимальное количество DNS серверов (6?), которые собственные и разбросаны по миру (имеет ли это смысл?)
— DNS зона содержит в себе максимальное количество A и AAAA записей (32?) дабы получить DNS round-robin.
— На каждом адресе, указанном в DNS, висит load-balancer (аппаратный или же софтовый? как load-balancer определяет какой сервер выдать, как он определяет самый менее нагруженный сервер?)
— Каждый load-balancer заведует неким количеством ngnix-серверов (или какой-то другой софт, если да, то какой? как ngnix может выбрать сервер самый менее нагруженный?)
— ngnix-сервер заведует неким количеством web-серверов, которые собственно дают контент.
— Каждый web-сервер имеет на машине Apache HTTP, PHP или Ruby и локальный memcached (или локальный не стоит?)
— За web-серверами стоят 2 вида баз данных — там где хранятся связи между объектами и собственно сами объекты. Все из них по условию должны уметь масштабироваться горизонтально.
— В качестве распределенного хранилища объектов используем что-то вроде memcacheDB или BigTable (или какую-то другую? т.е. у каждого объекта есть уникальный ключ, несущий в себе не только ID объекта как таковой но и информацию о типе объекта)
— В качестве распределенного хранилища связей нужно использовать какую-то БД на основе графа (правильно? если да, то какую?)
— Имеется также 2 набора memcached серверов которые кешируют запросы к обоим видам БД.
Хабралюди, мыслю ли я в правильном направлении? Что я не учел? Где почитать? Кто уже делал? Помогите просветлиться в этом.
Здравствуйте. Есть более или менее стандартный LAMP-сервер на Ubuntu Server, на котором крутится десяток сайтов.
Каждый сайт живёт как отдельный виртуальный хост Apache2 с модулем php5, Apache работает от одного юзера www-data. MySQL-база у каждого сайта отдельная и доступ к ней сделан через отдельного MySQL-юзера.
Вопрос к знатокам: каким образом померить моментальную (или за небольшой период) нагрузку, создаваемую каждым сайтом (понять сколько памяти, процессора, а может быть даже и диска он съедает)?
{kind=link}
{kind=link}
{kind=link}